由于线上每天产生的数据量已经让现有的存储设施不堪重负,ceph项目着急上线用以缓解压力,性能优化告一段落,接下来进行了上线前稳定性测试和上线准备,最重要的莫过于集群的运维工作,其中监控和告警为首要任务。
写在前面
松鼠哥的ceph专业课程上线啦!
面向新手同学,从0实战,全面入门ceph安装部署与运维,有需要的同学赶紧联系松鼠哥订购吧:
监控集群的重要性不言而喻,要求能够快速知晓集群当前或者过去一段时间的情况,掌握集群的信息并在集群出问题时提供重要线索,告警则能够在集群异常的第一时间通知到相关人员来处理,保障线上业务的持续和数据的安全性
框架选型
目前市面上流行的监控框架有不少,有老牌的zabbix,目前我们大部分就是用zabbix来进行监控管理和告警,zabbix在我做测试那段时间并没有接触过,给人的感觉就是很复杂,功能很多但是操作很繁琐,要上手是要花些功夫的,而且随着业务的发展,横向拓展zabbix之后的运维工作那才是苦不堪言。
还有一个档次很高的sysdig,有开源版和商业版,界面非常漂亮,使用方便而且功能强大,不过我们没有打算采用它
在新集群开始的阶段,我们就选择了Prometheus和Grafana的方案,exporter就使用ceph-mgr的prometheus模块和node_exporter,小巧但是功能足够强大
安装部署
ceph节点
在ceph-mon节点开启ceph-mgr的prometheus模块
1 | ceph mgr module enable prometheus |
这样就开启了ceph的exporter,它会收集集群信息并整理成prometheus格式
接下来安装node_exporter,它是用来采集系统级的信息并整理成prometheus格式
1 | wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz |
这样就启动了node_exporter,不过,这样的方式启动似乎很不专业,更好的办法就是为node_exporter做成一个systemd的service
1 | [Unit] |
Prometheus节点
Prometheus其实就是一个时序数据库,它与influxdb的最大却别在于,influxdb采用被动式数据获取方式,运行在各个被监控节点上的agent进程采集到数据后,直接推送给influxdb,influxdb来者不拒地接收并存储这些信息,而prometheus采用主动式的数据获取方式,每隔一段时间就会去运行了exporter的节点上pull数据并存储起来,两者相比,prometheus的管理更方便,尤其是监控节点数很多时,要修改取数据间隔的时候,谁用谁知道。
Prometheus的安装配置
1 | wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.linux-amd64.tar.gz |
配置prometheus,直接打开prometheus的yml文件,在scrape_configs域配置exporter的信息,即可完成配置,注意缩进
1 | vim prometheus.yml |
配置完成即可启动prometheus
1 | nohup ./prometheus & |
这样就把prometheus启动起来了,这里启动的方式也很不专业,还是做成systemcd的service比较好
1 | [Unit] |
prometheus启动后,默认监听9090端口,于是在浏览器打开即可浏览
打开后可查看各个target是否连接成功
查看是否到target成功拉到数据:
ceph-mgr的exporter情况
node_exporter情况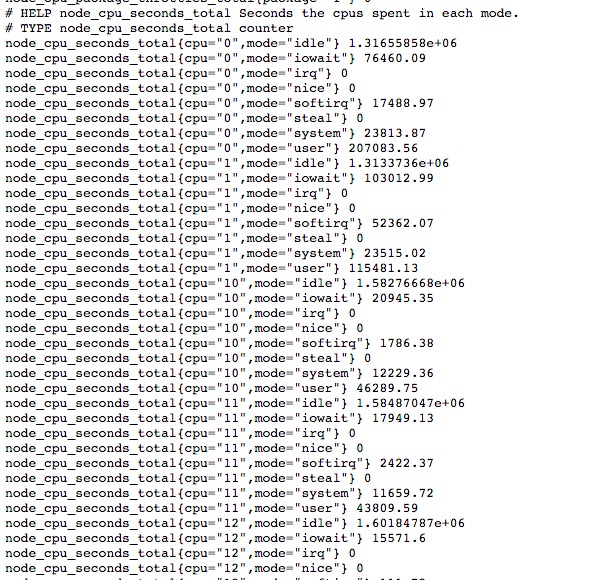
至此,监控数据收集和存储就完成了,接下来就是要使用图形化的工具来展示这些数据,以帮助我们快速了解到集群的信息,我们使用Grafana来做
Grafana
Grafana是一个图形化工具,它可以从很多种数据源中读取数据信息,使用很漂亮的图表来展示数据,并且有很多开源的dashborad可以使用,制作自己的dashboard也很简单,总之,可以快速地搭建起一个高逼格的监控平台
Grafana安装
这里我将Grafana安装到prometheus相同的机器上,事实上为了数据可靠性,不安装在同一个机器是比较好的选择
1 | wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.1.3-1.x86_64.rpm |
这样就完成了Grafana的安装启动,灰常地简单,接下来就是对Grafana的配置,首先打开它的web
使用admin/admin即可登录,登录后首先添加prometheus数据源
添加数据源通常不需要太多配置,配置一下名称和地址就可以了
配置完需要测试一下是否可用,如果不可用,需要检查一下是不是网络问题或者防火墙问题,测试通过后,即可创建dashboard,这里,使用导入dashboard的方式来创建dashboard,因为自己一个一个创建面板是个十分无聊又耗时间的事情,所以找个差不多的dashboard然后进行修改即可
获取dashboard
在Grafana dashboard上可以获取到很多其他人上传的dashboard,只需要搜索对应的数据源和exporter的dashboard即可拿来初步使用,注意,如果prometheus和node_exporter版本与dashboard规定的不一致,其使用的数据会有差别,会导致数据显示异常,这个后面可以解决
这里选择非常多人用的一款Docker and system monitoring,然后点击”Copy ID to Clipboard”就可以复制该dashboard的ID,然后在我们自己的grafana上使用该ID就可以自动下载并导入该dashboard,非常方便
导入的时候需要手动选择prometheus数据源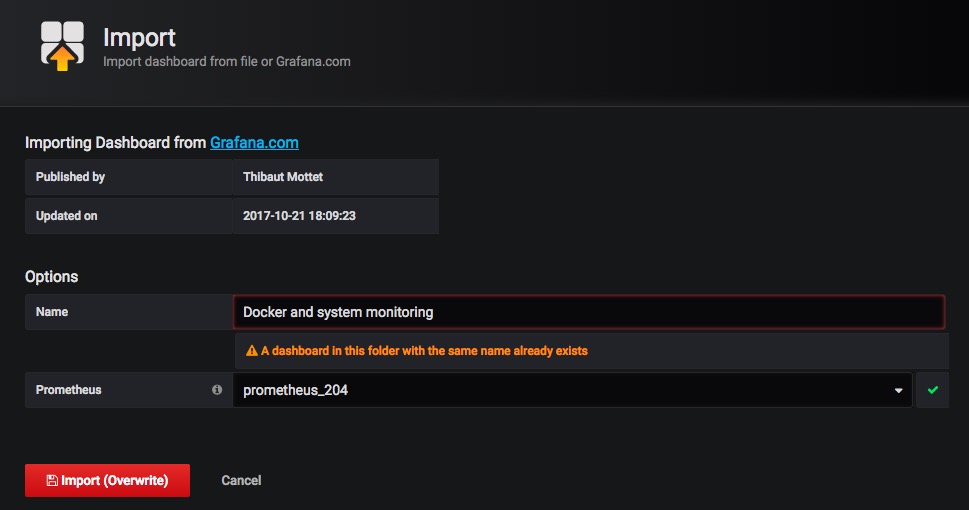
加入导入dashboard后出现下面的情况,数据显示异常
这说明面板的数据源有问题,prometheus的版本不一致会导致数据字段的变化,使得面板数据获取失败,修改数据源和数据字段就可以适配了
数据字段如果不熟悉,可以参照上面,打开promethues的target,然后查找字段相似的数据就行了
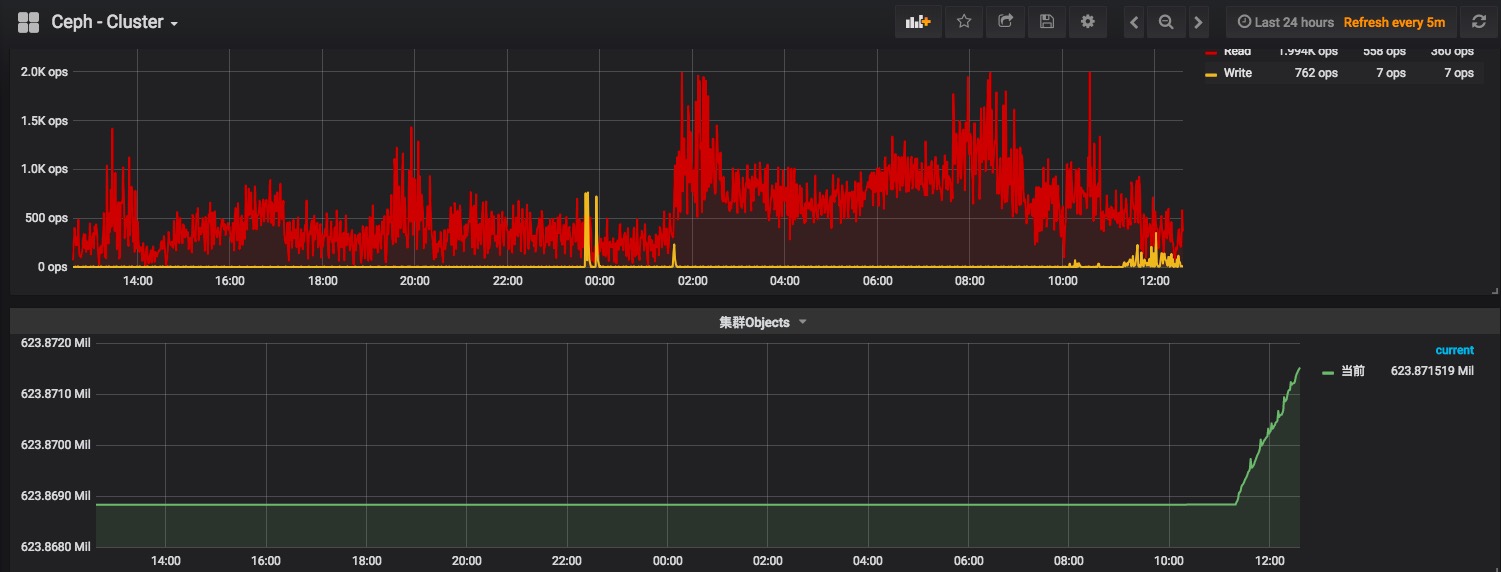
ceph相关的dashboard比较少,尤其是使用ceph-mgr的exporter,能够直接来用的dashboard没有找到,所以需要找差不多的,然后进行大量修改,对集群关注的指标进行手工添加dashboard,实现监控,目前我们环境中的dashboard,对系统和集群进行了划分,便于管理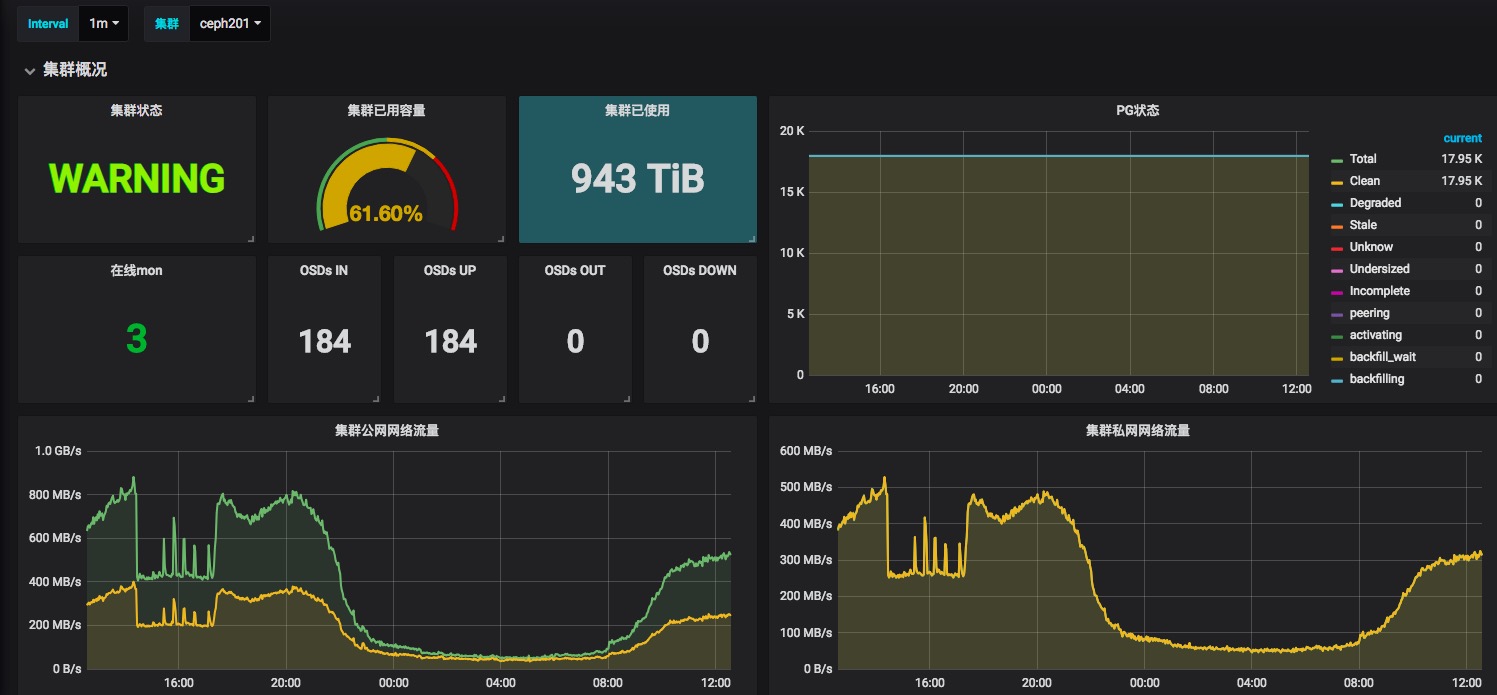
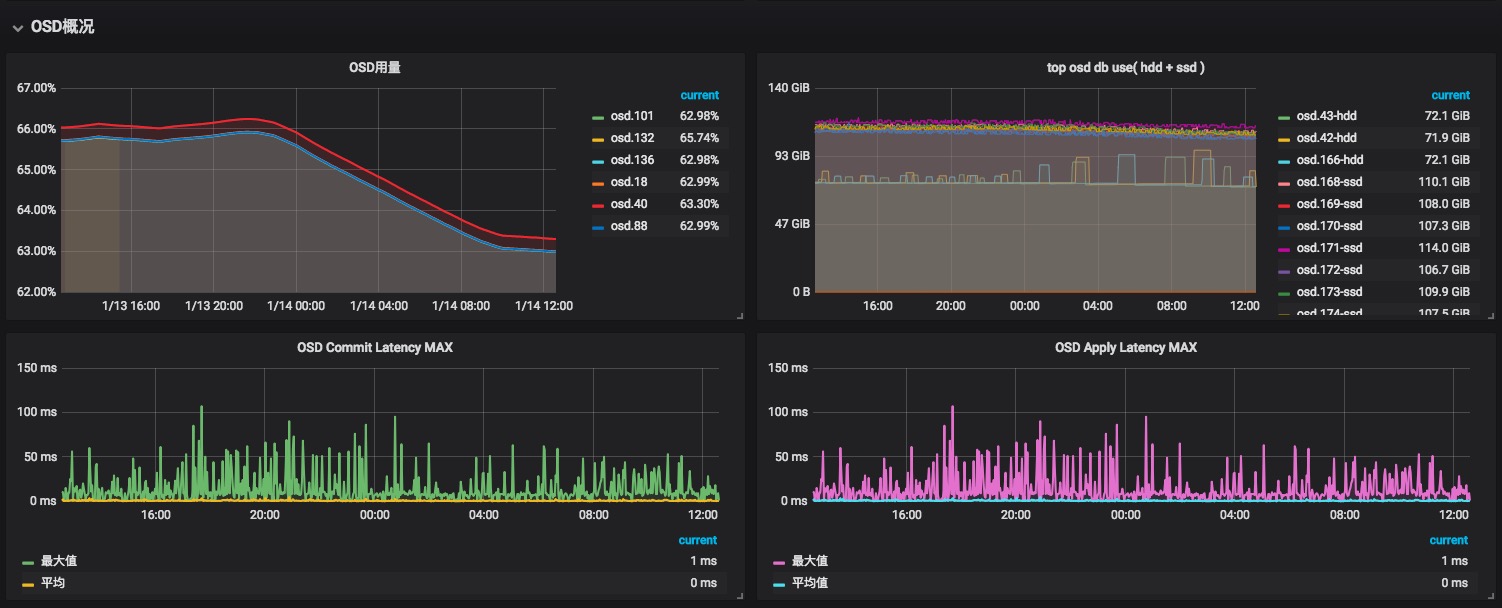

参考资料


- 本文作者: 奋斗的松鼠
- 本文链接: http://www.strugglesquirrel.com/2018/06/01/使用Prometheus和Grafana监控集群/
- 版权声明: 本博客所有文章除特别声明外,创作版权均为作者个人所有,未经允许禁止转载!